Talk to Your Mesh: Hands‑Free Speech Commands for Meshtastic

Why Speech Command?
Voice control is everywhere at home—lights, fans, assistants—but it’s still rare in offline, low‑bandwidth outdoor mesh.
Adding a local, on‑device Speech Command layer to Meshtastic means you can trigger actions by speaking—even with gloves on, hands busy, or eyes up in the field. Spoken intent becomes compact, low‑bandwidth commands, speeding up response and laying the groundwork for richer, domain‑specific voice interactions.
Challenge of Speech Command in Mesh
Unlike typical smart home devices—which rely on cloud-based speech recognition and constant power—Mesh devices are designed for outdoor, low-power scenarios, often with limited or no network connectivity. This brings several unique challenges:
- Offline operation: Speech recognition must run locally on the device, so it works even without a network.
- Low power: The system needs to operate with minimal energy to maximize battery life.
- Environmental noise: Outdoor noise can impact recognition accuracy.
- Limited compute resources: Mesh devices have constrained processing power and can't run large, complex models.
We needed a lightweight speech recognition module that runs efficiently under these constraints, while still delivering reliable accuracy and fast response. Based on these requirements, we built a demo version of Speech Command integration and tested it on Meshtastic devices.
How to Build It
The following sections detail how the Speech Command module was implemented and integrated into Meshtastic devices.
Hardware Selection
We chose the FoBE Mesh Tracker C1 as the test platform because it’s based on the nRF52840, giving enough compute headroom for a lightweight on‑device speech model while keeping excellent energy characteristics for outdoor use. Its flexible expansion interface lets us snap in a microphone module quickly for audio capture.

Installation is trivial: insert the flex microphone board into the expansion connector and press to lock—no soldering, no wiring.

With that, the hardware platform is ready.
Software Integration
To validate feasibility we started with a small, universal speech command set rather than continuous speech: simple directional intents ("go", "backward", "left", "right", "up", "down") mapped to device actions.
We first needed a training dataset. We used Google’s Speech Commands v0.02 corpus—short, single‑word audio clips ideal for tiny, resource‑constrained models.
Download: Speech Commands v0.02
After extracting, each folder represents a label. We selected the six folders: go, backward, up, down, left, right as our initial intent set.
We needed a lightweight inference stack that runs on nRF52840 and supports fast iteration of command sets. Edge Impulse was the obvious choice: a full TinyML pipeline (ingest → preprocess → feature extraction → train → deploy) with export options for embedded targets.
Public project: arduino-voice-command
On the Edge Impulse project we uploaded the selected clips from Speech Commands and used built‑in preprocessing + feature extraction blocks.
Uploads can be done via the Edge Impulse CLI or the web UI. After ingestion we verified labels to ensure each sample maps to the correct intent class.
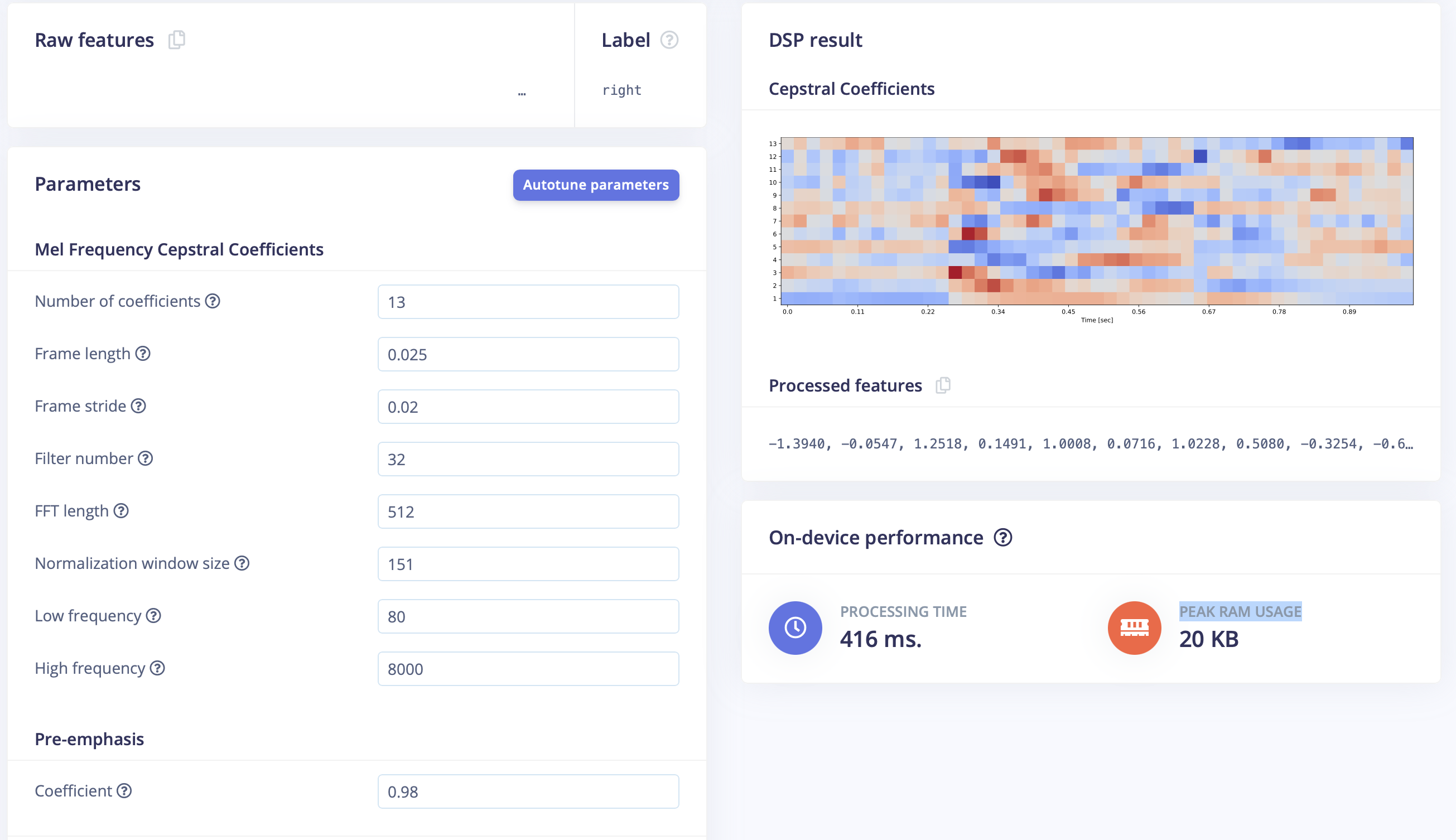
Next we performed MFCC feature extraction. Peak RAM usage was the primary constraint on nRF52840. We used 13 MFCC coefficients with tuned frame length / stride parameters to balance time resolution and memory footprint—enough discriminative power without blowing the buffer.
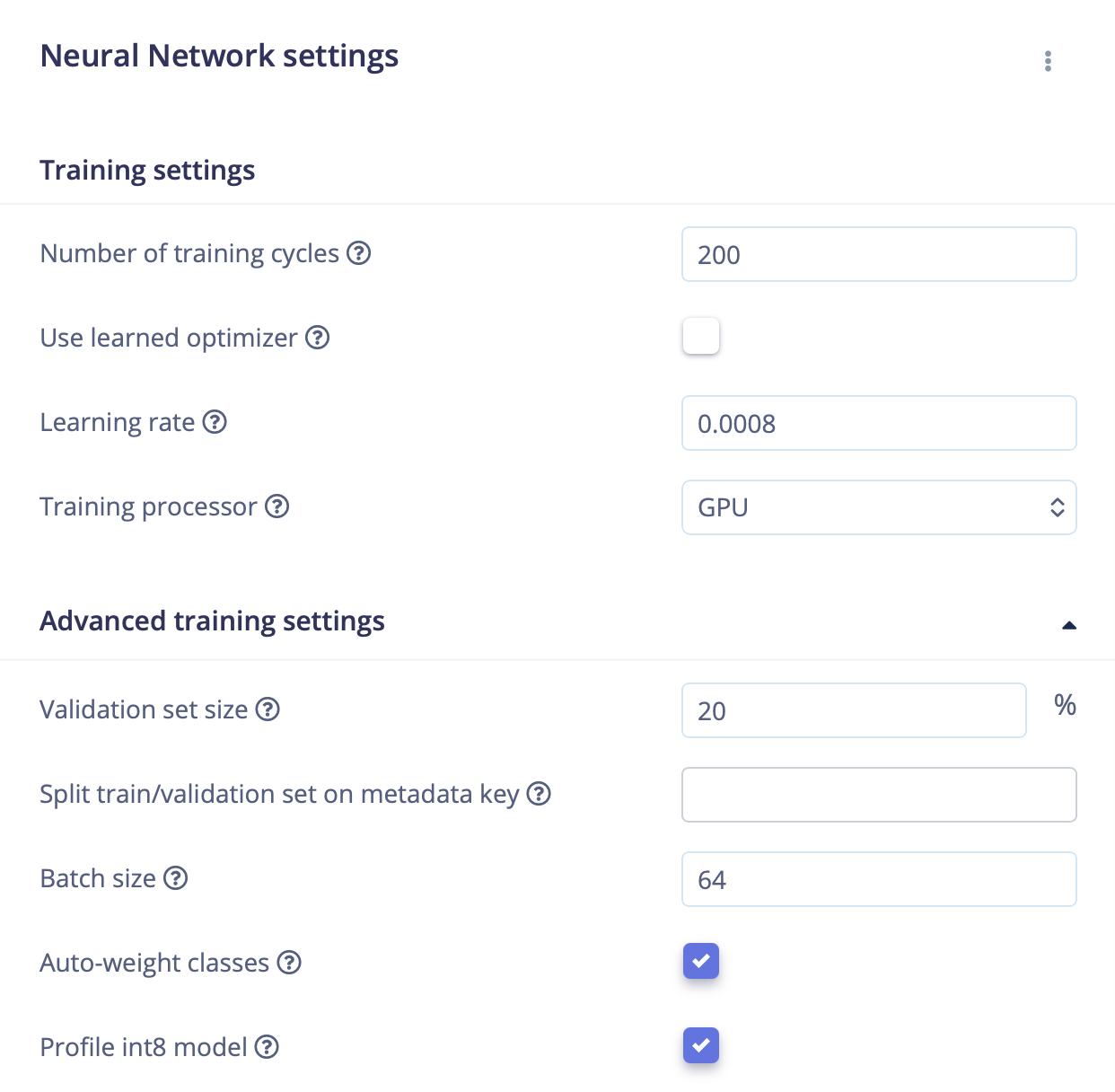
We then trained a lightweight 1D CNN on the extracted features. Hyperparameter tuning focused on the trade‑off between model expressiveness and embedded latency so it can run real‑time on nRF52840 while maintaining strong accuracy.
| Parameter | Description | Value | Purpose |
|---|---|---|---|
| Number of training cycles | Epoch count | 200 | More passes improve learning; too many risk overfitting. |
| Learning rate | Step size for updates | 0.0008 | Lower = stable convergence; higher = faster but risk oscillation. |
| Training processor | Accelerator | GPU | Speeds up training substantially. |
| Validation set size | Hold‑out proportion | 20% | Monitors generalization on unseen data. |
| Batch size | Samples per update | 64 | Balances stability vs. memory usage. |
| Auto-weight classes | Class balancing | Yes | Mitigates imbalance across labels. |
| Profile int8 model | INT8 quantization | Yes | Produces a compact, faster inference model. |
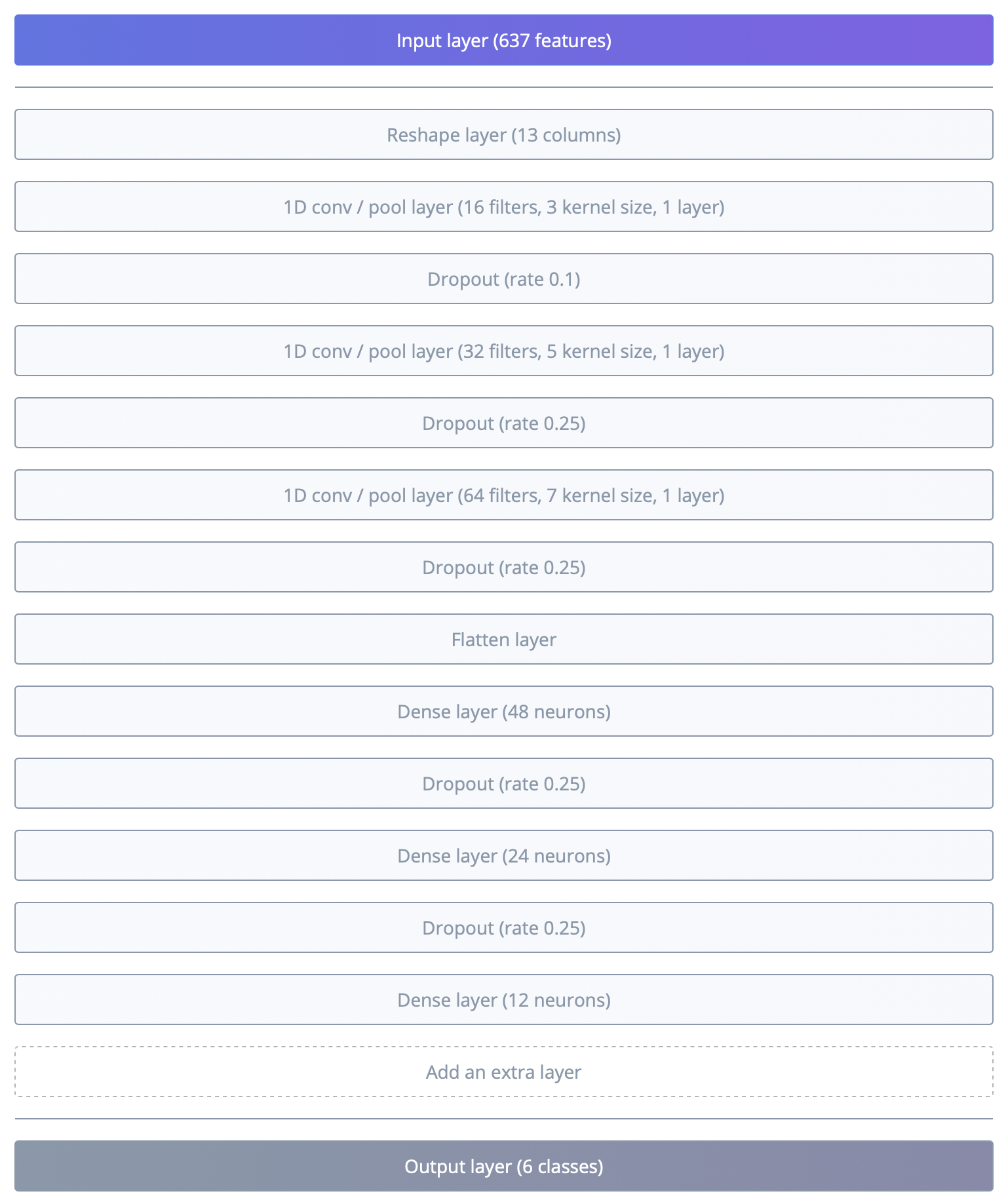
| Layer | Type | Params | Notes |
|---|---|---|---|
| 1 | Input layer | 637 features | Raw feature vector |
| 2 | Reshape layer | 13 columns | Shape for temporal conv |
| 3 | 1D conv / pool layer | 16 filters, kernel=3 | Local feature extraction |
| 4 | Dropout | rate=0.1 | Regularization |
| 5 | 1D conv / pool layer | 32 filters, kernel=5 | Deeper temporal patterns |
| 6 | Dropout | rate=0.25 | Regularization |
| 7 | 1D conv / pool layer | 64 filters, kernel=7 | Higher‑level semantic features |
| 8 | Dropout | rate=0.25 | Regularization |
| 9 | Flatten layer | — | Collapse to 1D |
| 10 | Dense layer | 48 neurons | Integrate features |
| 11 | Dropout | rate=0.25 | Regularization |
| 12 | Dense layer | 24 neurons | Compress representation |
| 13 | Dropout | rate=0.25 | Regularization |
| 14 | Dense layer | 12 neurons | Pre‑output layer |
| 15 | Output layer | 6 classes | Final classification |
Clicking Save & Train starts the job on Edge Impulse. The resulting metrics on both train and validation sets are strong, indicating the model reliably separates the six intents.
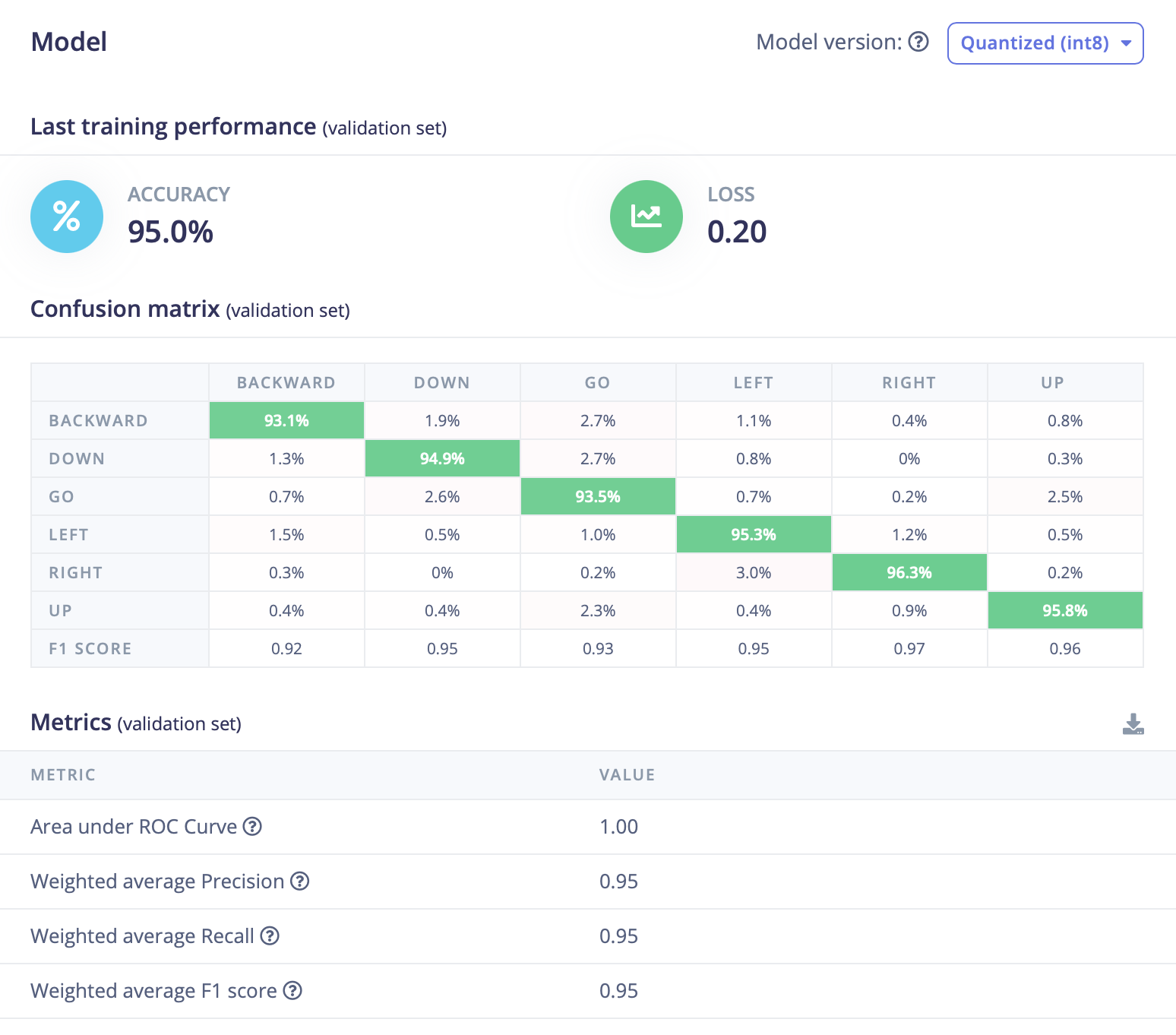
Overall performance
- Accuracy: 95.0%
- Loss: 0.20
This reflects high validation accuracy with a low loss—accurate and well‑converged.
| Class | Accuracy | Notes |
|---|---|---|
| BACKWARD | 93.1% | Minor 2.7% confusion with "GO"; overall solid. |
| DOWN | 94.9% | Very good; minimal confusion. |
| GO | 93.5% | Small confusion with "DOWN" / "UP" suggests similar patterns. |
| LEFT | 95.3% | Clean and stable separation. |
| RIGHT | 96.3% | Among the best performing classes. |
| UP | 95.8% | Also very consistent. |

The built model uses about 71.6 KB flash and 7.4 KB RAM, which fits comfortably on the nRF52840.
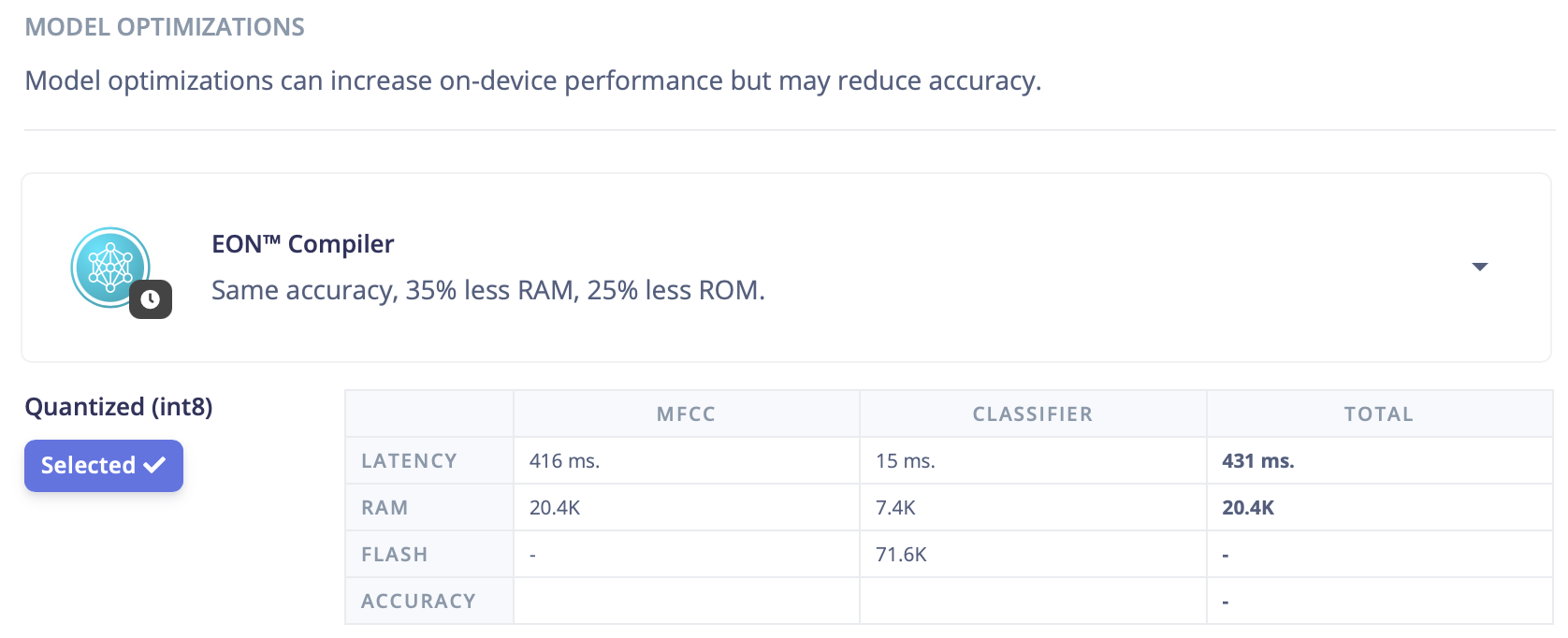
Finally, export the model as an Arduino library and drop it into the Meshtastic firmware tree for integration.
For a working reference inside Meshtastic firmware, see our example variant: fobe_idea_mesh_tracker_c1_voice
In this variant we add microphone support and integrate the exported Edge Impulse model. By adjusting the main loop, the firmware listens for speech commands and dispatches actions—e.g., send a message or control local functions—when a target intent is detected.
What Next?
This demo validates on‑device Speech Command for Meshtastic under tight resource and power constraints. Next directions:
- Richer command space: expand from 6 intents toward letters (A–Z), numerics (0–9), or semantic tags (status, location, SOS).
- Adaptive models: dynamically load / prune command subsets by role or mission profile to keep RAM/flash overhead minimal.
- Noise robustness: dual‑mic (beamforming), spectral denoise, multi‑window voting to resist wind and impact noise.
- Multilingual & customization: user‑specific fine‑tuning or few‑shot on‑device adaptation for accent / language variants.
- Reliability safeguards: confidence thresholds + optional fallback (e.g., button confirm when below margin).
- Lower power: refined duty‑cycling, wake‑word gating before feature extraction, and peripheral clock scaling to extend battery life.